Search and Browse
The searching and browsing interface provides means for the exploration and querying of the items contained within the different archives. The user is able to query by text and collection. Browsing functionality allows the user to obtain an overview of what items are within the collections before conducting specific queries.
Search
The searching functionality saw the implementation of a text-based search supported by the implementation of auto-complete functionality. The auto-complete functionality was implemented by storing a .json file on the server containing a list of words to be used for the auto-completion. The words within these files was drawn from the metadata of the multimedia items contained within the archives.
The search interface also alowed users to query within a specific category. An option to limit the search to a specific result set was also implemeneted
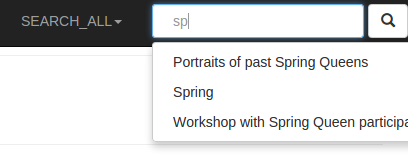
Figure 1: A snippet of the interface inidcating the search bar with auto-complete suggestions
Browse
Browsing functionality considered the Dublin Core metadata fields and used these as categories that the archival items were grouped into. This categorisation can be viewed in the left-hand pane of Figure 2. This allowed exploration by these specific categories. The categories present only reflected information contained within the archives therefore ensuring no appearance of empty categories.
Figure 2: Overall browsing interface
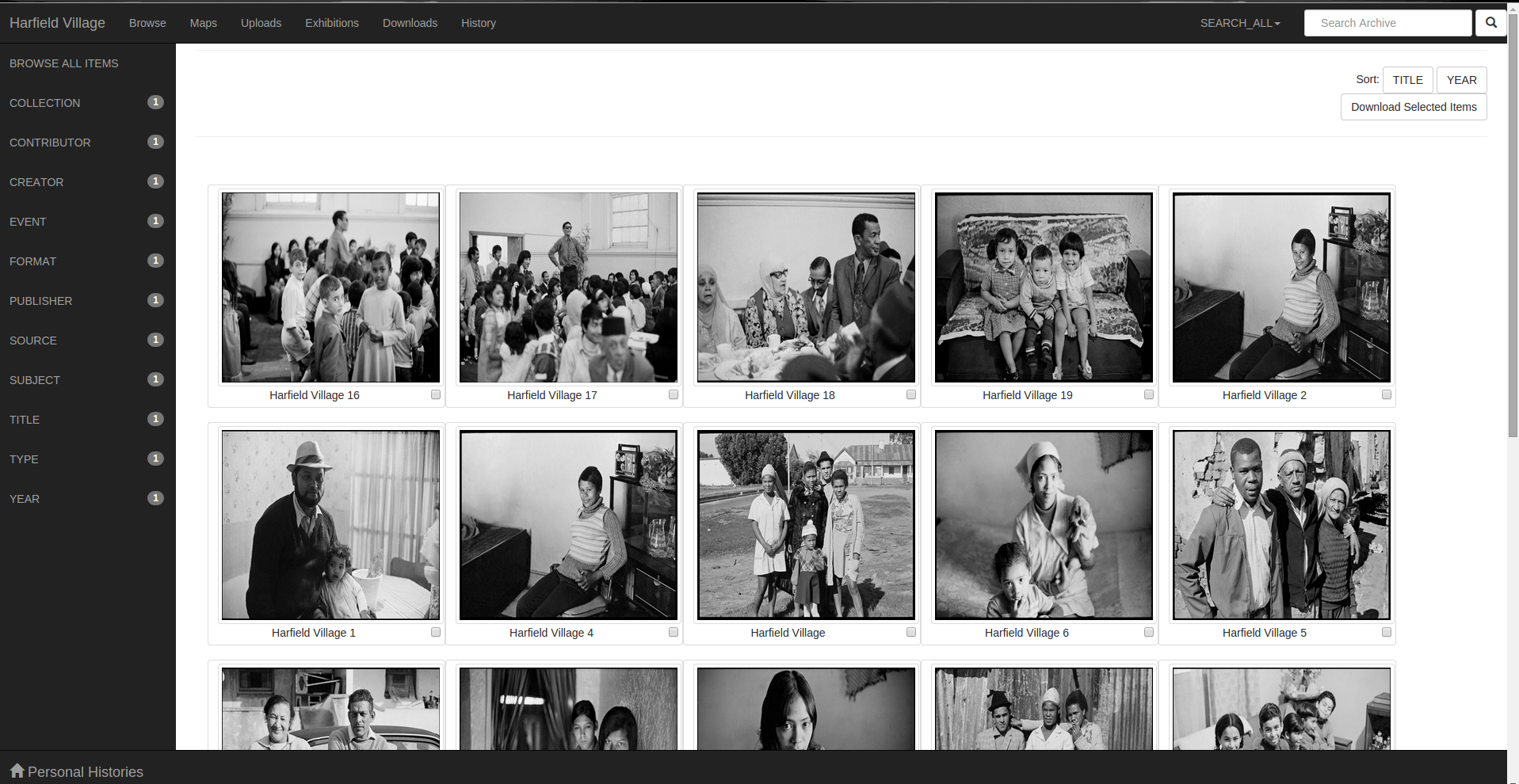
Figure 3: Browse by Event
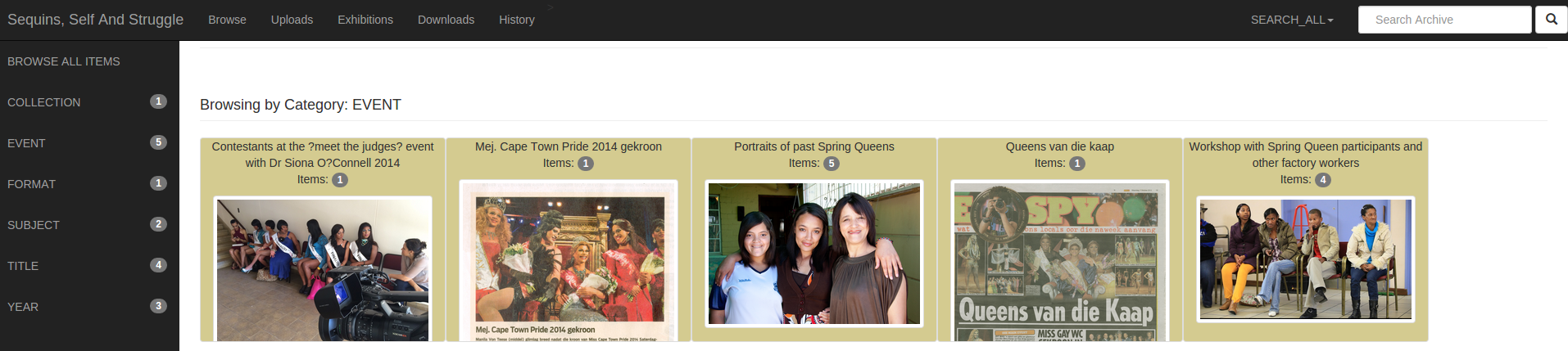
Figure 3 illustrates what would occur when a user clicks on one of the browsing categories. The items are then grouped in sub-categories in the form of folders.
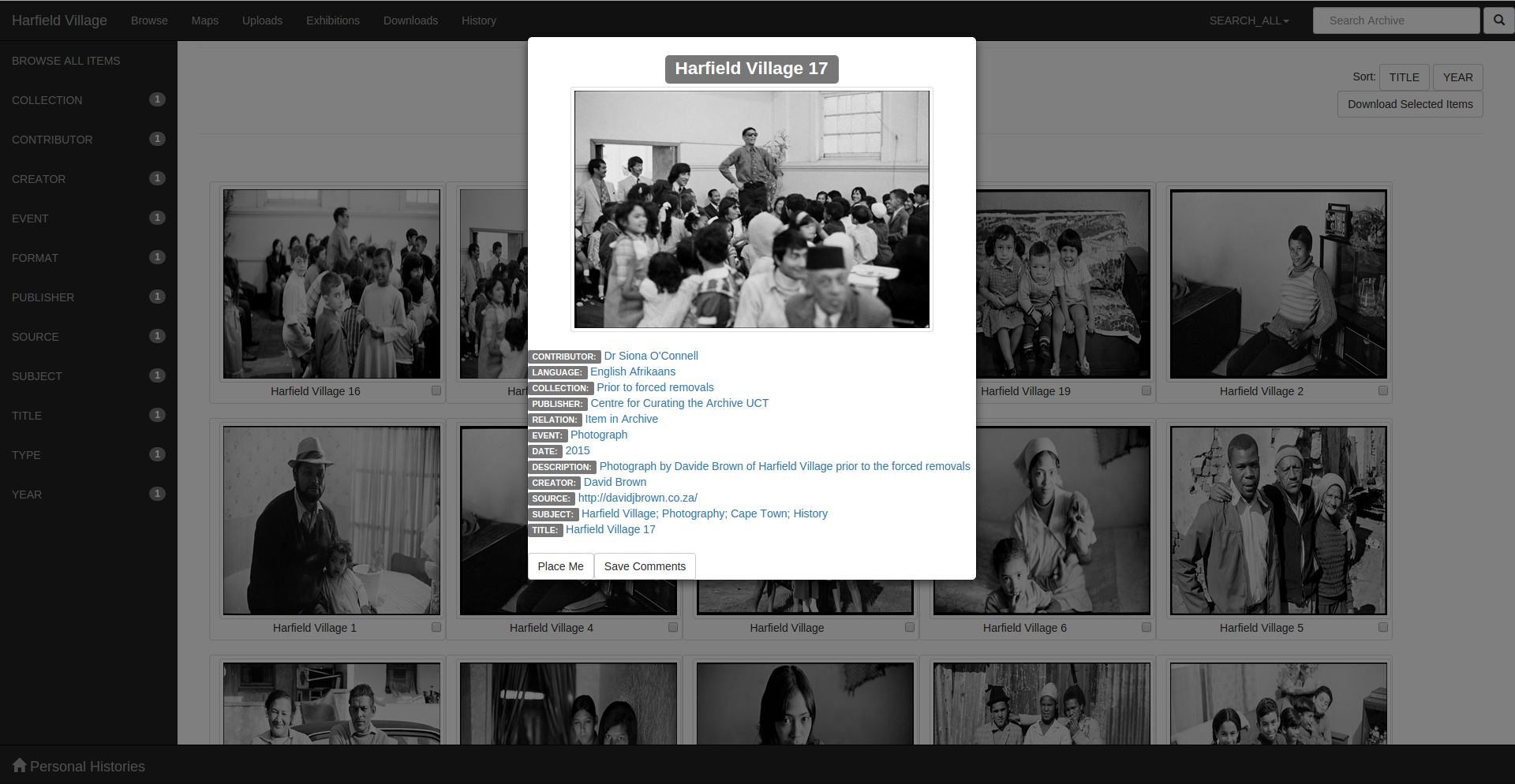
On clicking on a specific archival item, the user would be presented with a dialog as below. This provides the user with the metadata for that item. The metadata values within this dialog are links allowing the user to explore related items through this medium.
Figure 4: System response on clicking on a specific archival item
Implementation
Search and Browse implementation used the Fedora digital object repository as well as the Solr search engine. The Fedora Digital object repository allowed for the storage and management of the digital objects within the archive. A Fedora client was written in Java in order to interface with the RESTful API provided by Fedora. The image below indicates which methods were developed to interact with the RESTful API. The methods focussed on were those responsible for the retrieval of data from the archive. These include:- findObjects
- getDatastreamDissemination
- listDatastreams
- getDatastreams
- getDatastreamHistory
- getObjectXML
Figure 4: Domain Class image of FedoraDigitalObject

Figure 5: Fedora Digital Object properties as per the Fedora Commons project
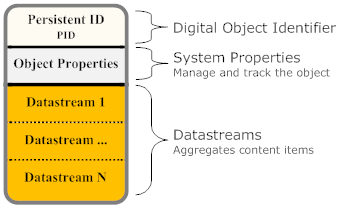
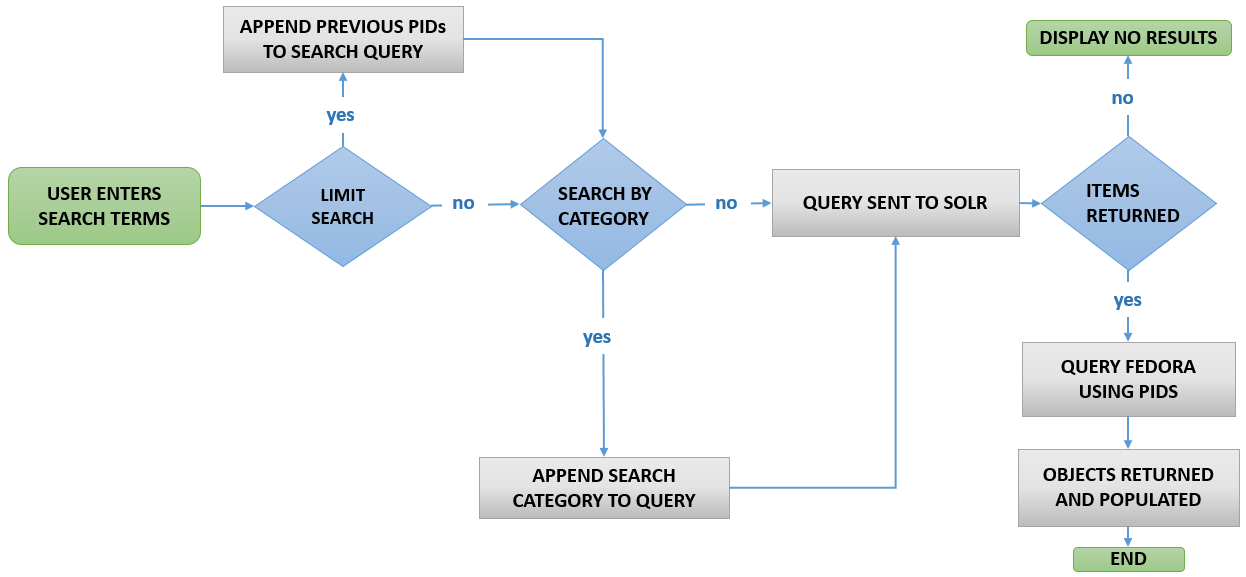
The use of Fedora was combined with the use of the Solr search engine. Fedora provided storage and management of diigital objects, and Solr was used for indexing and increased querying capabilities. Solr returned a resultset in the form of a json file. The PIDs was extracted from this and queried using the Fedora repository in order to obtain fuller information to be used to populate the FedoraDigitalObjects. A flow of events when conducting a search using the system can be observed below.
Figure 1: Flow diagram
Technologies used
- Java
- Fedora
- Solr
- FedoraGsearch
- Jquery
- Javascript
Evaluation and Results
Evaluation of the features took place in the form or User Acceptance testing, usability testing and the implementation of automated tests using the Junit testing framework.User Acceptance Testing
The user acceptance testing involved users at the Centre for Curating the archive performing various tasks using the system to test the functional requirements. The funtionality assessed and passed is as below. Detail on the questions and tasks conducted are as per Evaluation Documentation downloads. The below indicates the functional requirement assessed and results obtained.Search Functional Requirements
| Functionality | Pass or Fail |
| Text-based search | Pass |
| Auto-complete | Pass |
| Limiting search scope | Pass |
| Using links/tags to naviage | Pass |
| Sorting results | Pass |
| Searching using categories | Pass |
Browse Functional Requirements
| Functionality | Pass or Fail |
| Browsing the images | Pass |
| Browsing using categories | Pass |
| Viewing metadata for each item | Pass |
| Use of metadata to assist browsing | Pass |
Usability Testing
The usability testing involved presenting 15 with a set of tasks to complete and then a questionairre to complete after their interaction with the system. The questionairre and detailed results can be obtained via the downloads section under the evaluation documentation. A summary of results can be found below. The results are ranked from 1 to 5 where 1=strongly disagree and 5=strongly agree.| Criteria | Client | Expert | Student | Other | |
| Usefulness | 3.92 | 3.54 | 3.9 | 3.96 | 3.83 |
| Ease of Use | 4.09 | 4.15 | 3.62 | 3.73 | 3.89 |
| Ease of Learning | 4.25 | 4.58 | 3.92 | 4.17 | 4.23 |
| Satisfaction | 3.94 | 4 | 3.36 | 3.67 | 3.74 |
Conclusions
Conclusions drawn from the results above include full acceptance of the functionality implemented. The usability tests indicate that the user's agreed with the ease of learning and ease of use of the functionality. The satisfaction lies closer to the agreement mark. The overall average amounts to 3.94 indicating that the system is usable.Future Work
Future work for the services implemented would involve a multi-lingual archive for the search and content based image retrieval. In addition, searching and browsing by exhibition could be a category to be included since one of the archive's main features is the ability to create and view exhibitions. Future work includes the introduction of a faceted search allowing multiple filters to be applied simultaneously.
